| |
U |
C |
A |
G | |
|---|
| U |
F
F
L
L |
S
S
S
S |
Y
Y
*
* |
C
C
*
W |
U
C
A
G |
|---|
| C |
L
L
L
L |
P
P
P
P |
H
H
Q
Q |
R
R
R
R |
U
C
A
G |
|---|
| A |
I
I
I
M |
T
T
T
T |
N
N
K
K |
S
S
R
R |
U
C
A
G |
|---|
| G |
V
V
V
V
|
A
A
A
A |
D
D
E
E |
G
G
G
G |
U
C
A
G |
|---|
| |
U |
C |
A |
G | |
|---|
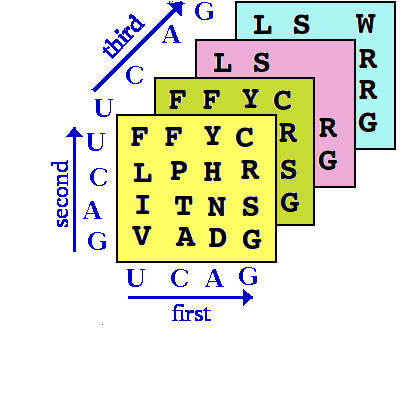
On the left is the Genetic Code in a form commonly seen in biochemistry
text books. The coloured entries are amino acids; * represents
a termination codon or "nonsense codon" for which
there is no amino acid but these codons are "full stops"
in the code. This representation is a rather unsuccessful attempt
to draw a 3D matrix
in 2D. Let each codon be N1N2N3:
N1 (U, C, A or G) is in the largest font (left column);
N2 next (top row) and N3 in the right hand
"column". There are clearly 43 codons. For any
one base, e.g. C, there are 16 codons CXX. Fixing N2 also,
there are 4 CAX codons constituting the "CA codon family".
The pattern of redundancy in the code is non-random.
In half of the codon families,
the
3rd base has no significance and in
most of
the rest it is determined only by whether the 3rd base is a pyrimidine
or purine. Three codons have
unique meanings.
Perhaps unexpectedly two "red"
codons have double meanings interpreted by their sequence context.
AUG is also an initiation codon and
UGA can encode the rare amino acid,
selenocysteine (the "21st amino acid").
Four footnotes/questions:
- Is the code Universal? Almost, this is the genetic code
from Escherichia coli.
- E. coli has an alternative initiation codon, GUG: in
its initiation context, GUG encodes M not V.
- Are all the codons for, say R, used equally? No and
moreover the patterns of codon usage are highly characteristic of
different genetic systems in the same organism and different
organisms.
- Surely there must be a better way of representing and looking
up the genetic code than this.
That is absolutely correct: the genetic code is actually a
3×3×3 array (right picture).
BACK to TOPIC 6